
- Lieu : Laboratoire de Physique de l’ENS de Lyon
- Encadrants : Adrien Meynard et Nelly Pustelnik
- Modalité de candidature : Adresser un mail à adrien.meynard@ens-lyon.fr
- Durée du contrat : 36 mois
- Date de début du contrat : Septembre 2026
- Salaire mensuel : Environ 2 300 euros brut.
Mots- clés : temps-fréquence, signaux non stationnaires, apprentissage de représentations.
Contexte
Construire une représentation adaptée à la structure d’un signal est essentiel pour en faciliter la description, l’interprétation et l’exploitation. Par exemple, la simple observation temporelle d’un signal audio ne suffit souvent pas à en révéler la nature, alors qu’une représentation temps-fréquence (TF) met immédiatement en évidence ses caractéristiques. Elle révèle notamment l’harmonicité, le rythme percussif ou les variations de hauteur. Un utilisateur expérimenté peut ainsi identifier visuellement la nature du son mesuré, qu’il s’agisse de la signature d’un instrument de musique, de l’espèce d’un animal ou d’un bruit urbain.
En bioacoustique sous-marine, l’analyse des vocalises de mammifères marins est un outil clé pour détecter la présence d’espèces et étudier leurs interactions [Montgomery, 2017]. Pour certaines espèces, ces sons non stationnaires peuvent être représentés [Meynard, 2018] à l’aide d’un modèle composé de deux éléments :
- un signal stationnaire sous-jacent (lié à l’appareil phonatoire), noté x;
- un opérateur temporel déformant le signal (représentant les variations de hauteur), noté
γ.
Le signal observé y est alors décrit par:
y(t) = x(γ(t)).
La connaissance de ces deux composantes est cruciale pour comprendre les sons émis. Elle permet, par exemple, de comparer les individus d’une même espèce ou d’identifier des motifs propres à une espèce.
Une méthode d’estimation classique repose sur l’analyse du comportement d’une représentation TF: la transformée en ondelettes (TO). Comme illustré à la figure ci-dessous, cette approche consiste à déterminer un déplacement vertical des coefficients dans le plan TF, permettant de retrouver le spectre du signal stationnaire sous-jacent (signature de la voix de l’animal) ainsi que l’opérateur déformant (signature du cri produit).
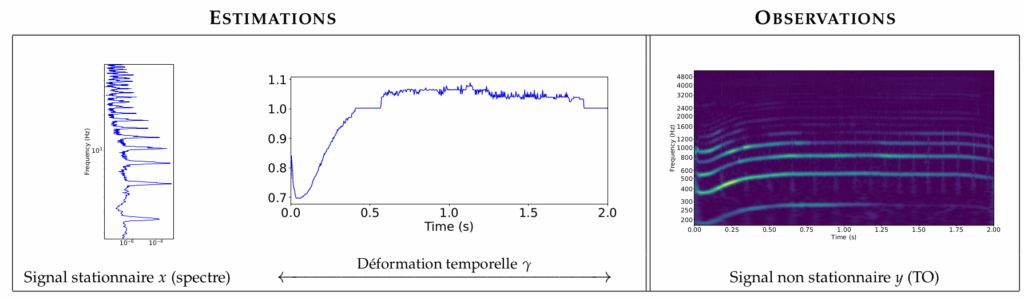
Ce modèle reste toutefois trop simpliste pour de nombreux signaux. Par exemple, des variations de hauteur trop rapides entraînent des interférences dans le plan TF, rendant impossible la caractérisation de la TO par les seules quantités à estimer. De plus, la présence de composantes superposées (comme les clics produits par un dauphin) ou mal représentées par le modèle choisi peut conduire à des estimations erronées.
Méthodologie
Nous proposons d’introduire des modèles plus généraux, mieux adaptés à la complexité structurelle de ces signaux. L’objectif est de construire de nouvelles représentations préservant les propriétés simples de déplacement vertical des coefficients dans le plan TF, tout en s’affranchissant de la linéarité des représentations classiques. Nous souhaitons également conserver l’interprétabilité et la facilité de visualisation associées aux représentations TF traditionnelles, comme la transformée en ondelettes.
L’apprentissage de représentation offre une piste prometteuse [Bengio, 2013]. Ces modèles d’apprentissage statistique (non linéaires) permettent de construire des représentations adaptées aux données complexes. Fondés sur des architectures de réseaux de neurones, ils bénéficient des avancées récentes en apprentissage profond, ce qui en fait une approche populaire pour l’analyse et la compression de signaux [Tschannen, 2018]. Ces représentations devront toutefois respecter deux contraintes essentielles :
- conserver une interprétabilité physique comparable à celle des représentations TF classiques ;
- limiter les risques de surapprentissage lorsque les jeux de données disponibles sont de taille réduite.
Une fois estimée, la représentation obtenue pourra être exploitée pour diverses tâches, notamment la classification automatique, par exemple pour distinguer des espèces animales.
Le projet s’articulera autour de l’objectif principal de développer de nouvelles représentations TF pour les signaux complexes. Nous aborderons prioritairement deux situations.
Objectif 1: Signaux à déformation temporelle rapide.
Nous nous intéresserons au signaux pour lesquels la déformation temporelle varie rapidement, causant l’apparition d’interférences dans les représentations classiques. Nous définirons un modèle non linéaire destiné à construire une représentation exempte d’interférences. Il reposera sur un réseau neuronal dont les sorties seront assimilables à des coefficients TF, contraints pour respecter la structure d’une représentation TF idéale. Nous intégrerons explicitement, comme a priori, la propriété de déplacement des coefficients observée dans la TO lors de variations de hauteur. L’objectif est que la nouvelle représentation conserve cette structure, y compris lorsque la déformation temporelle devient trop rapide pour les méthodes classiques. Une étape de reconstruction linéaire permettra ensuite de synthétiser le signal à partir de ces coefficients, formant ainsi un problème d’apprentissage autosupervisé.
Objectif 2: Signaux multi-composantes.
Nous adapterons l’approche précédente aux signaux constitués de plusieurs composantes. Si leurs contenus fréquentiels sont proches, des interférences entre composantes peuvent apparaître dans le plan TF classique. Pour les limiter, nous construirons une représentation TF apprise, visant à améliorer la lisibilité et l’interprétabilité des représentations obtenues.
Organisation
- La personne recrutée pourra commencer ses travaux dès le stage de master 2, qui constituera une introduction au sujet de thèse.
- Le stage et la thèse seront encadrés par Adrien Meynard, maître de conférences, et Nelly Pustelnik, directrice de recherche.
- La thèse s’inscrit dans le cadre du projet ANR TIPHAINE en collaboration avec le laboratoire Jean Kuntzmann (université de Grenoble-Alpes) et l’IRIMAS (université de Haute-Alsace). Des séjours au sein de ces laboratoires partenaires seront organisés afin de renforcer les échanges scientifiques et de favoriser les développements collaboratifs.
Référénces
- [Montgomery, 2017] J. C. Montgomery and C. A. Radford, “Marine bioacoustics,” Current Biology, vol. 27, no. 11, pp. R502–R507, 2017.
- [Meynard, 2018] A. Meynard and B. Torrésani, “Spectral Analysis for Nonstationary Audio,” IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 26, pp. 2371–2380, Dec. 2018.
- [Bengio, 2013] Y. Bengio, A. Courville, and P. Vincent, “Representation learning : A review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013.
- [Tschannen, 2018] M. Tschannen, O. Bachem, and M. Lucic, “Recent advances in autoencoder-based representation learning,” in Bayesian Deep Learning Workshop, NeurIPS 2018.



