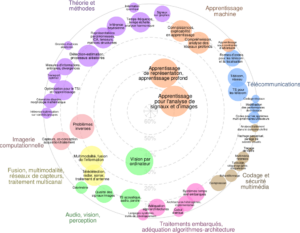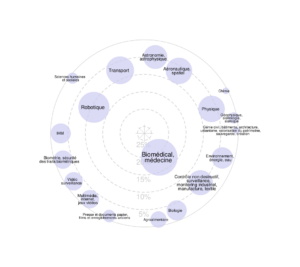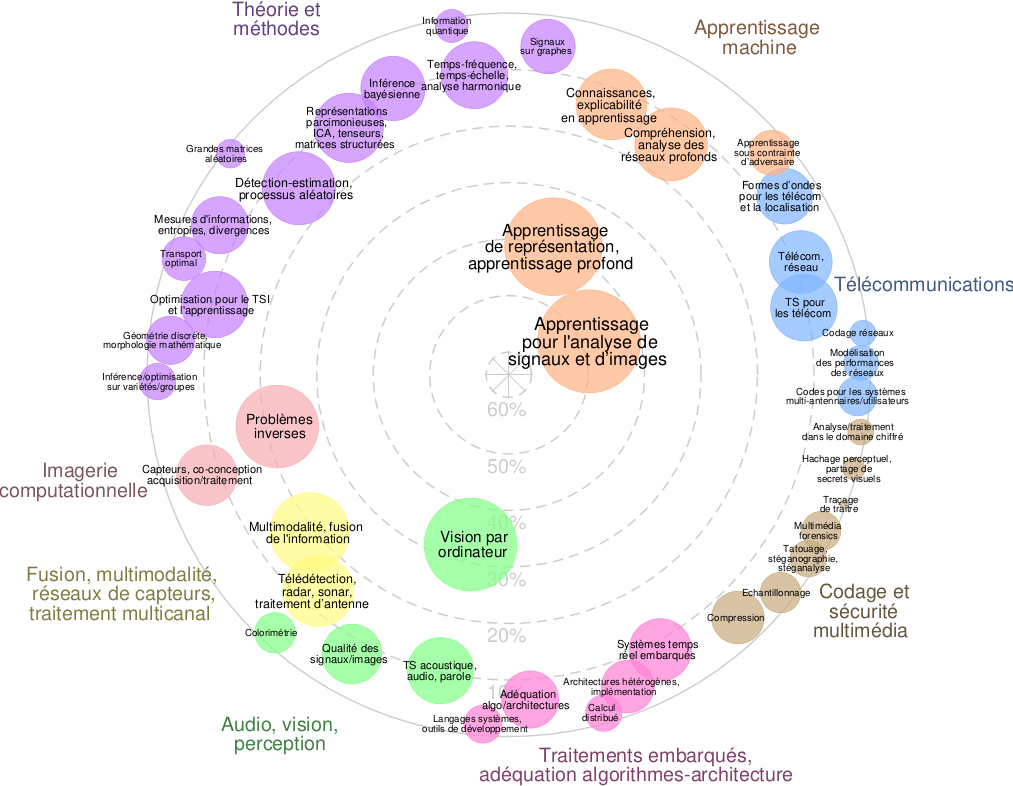
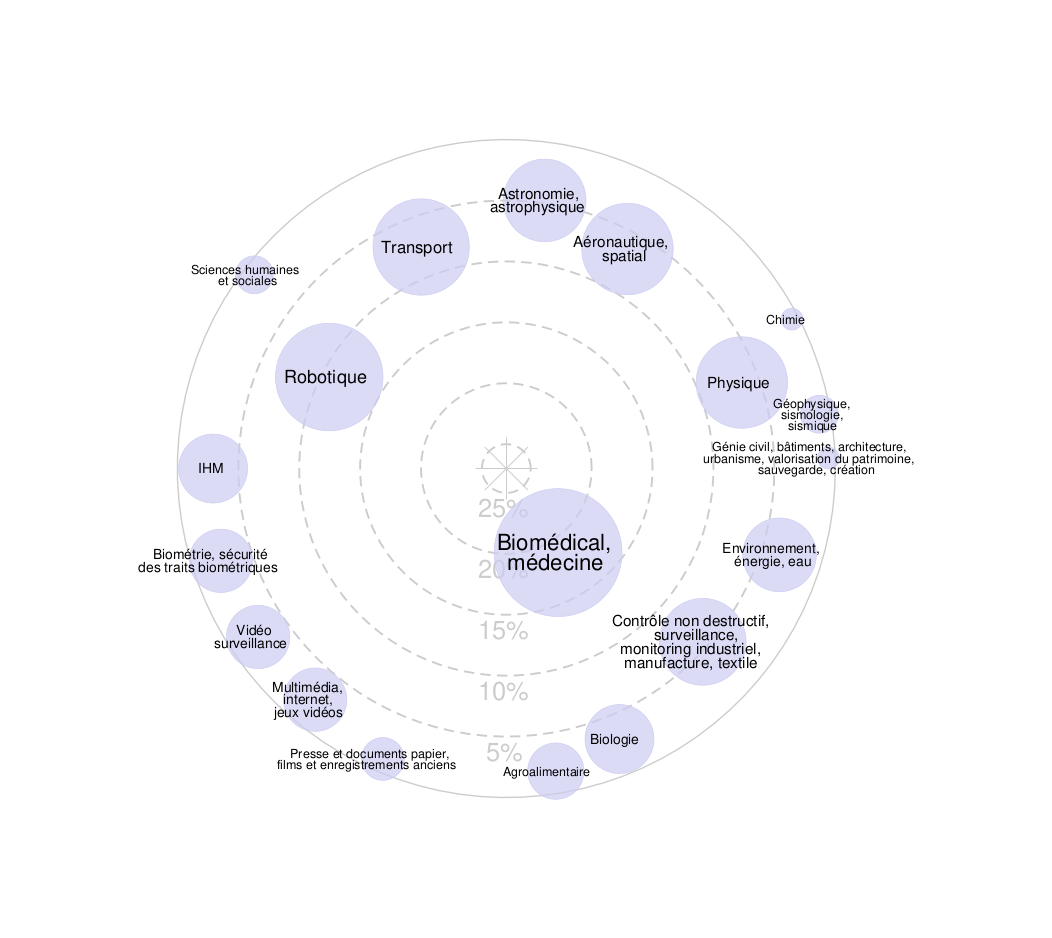
Assemblée Générale du GdR 2025
La prochaine Assemblée Générale du GdR se déroulera à La Grande-Motte Presqu’Ile du Ponant, du...

24 Octobre 2024
Catégorie : Stagiaire
The joint collaboration between LaTIM and Evolucare Technologies resulted in an automated algorithm that screens for ocular anomalies such as diabetic retinopathy, glaucoma and age-related macular de generation based on fundus photographs. The automated algorithm, whose performance reaches that of a retinal expert, is currently commercialized by OphtAI (www.ophtai.com), which was created by Evolucare Technologies (Villers Bretonneux, France) and ADCIS. It has been deployed in several clinical centers around the world, through the Evolucare Technologies cloud. The success of this solution is partly thanks to the large amount of annotated data collected from the OPHDIAT screening network in Île-De-France, namely 760,000 images from 100,000 diabetic patients. The goal of LaTIM and Evolucare Technologies is to expand screening to all pathologies affecting the eye, or visible through the eye (cardiovascular pathologies, neurodegenerative diseases, etc.). To this end, developing a foundation model based on fundus photographs is highly relevant, especially in the context of enhancing model generalizability [1].
In particular, Vision-Language foundation Models (VLMs) [2, 3] have shown exceptional ability to model and align the representations of images and text. These developments broaden the scope of potential applications, from visual question answering and image captioning to image-to-image retrieval. However, training these models typically requires corresponding textual descriptions, which are often missing in the medical domain. To address this challenge, Large Language Models (LLMs) are frequently employed to generate descriptions from tabular or categorical data, bridging the gap between structured medical information and the textual inputs needed for VLM training. In this work, we aim to optimize the performance of these LLMs in generating accurate and meaningful descriptions, ensuring they are well-suited for medical application. This optimization will enhance the ability of VLMs to learn from multimodal medical datasets, improving their generalizability and applicability to clinical tasks.
In this work, we will evaluate the performance of several local LLMs and promote engineering solutions to enhance their output. The selected candidate’ roles will include:
Send your resume, motivation letter and grades to Sarah Matta (sarah.matta@univ-brest.fr), Gwenolé Quellec (gwenole.quellec@inserm.fr) and Mathieu Lamard (mathieu.lamard@univ-brest.fr).
[1] Yukun Zhou et al. “A foundation model for generalizable disease detection from retinal images”. In: Nature 622.7981 (2023), pp. 156–163.
[2] Julio Silva-Rodriguez et al. “A foundation language-image model of the retina (flair): Encoding expert knowledge in text supervision”. In: Medical Image Analysis (2024), p. 103357.
[3] Meng Wang et al. “Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases”. In: arXiv preprint arXiv:2406.09317 (2024).