
Contexte
Le secteur agricole fait actuellement face à de nombreux défis et à des changements structurels accentués par la démographie, le changement climatique, l’impact environnemental, les modes de consommation, la compétitivité, etc. Pour y faire face, les technologies du numérique (la proxidétection/télédétection, les capteurs, le traitement du signal et des images, l’intelligence artificielle, la robotique…), se présentent comme un des principaux leviers. Ces dernières années, la possibilité d’acquérir de grandes bases de données, les capacités de calcul accrues ainsi que des avancées théoriques clés ont permis l’essor de nouvelles méthodes d’apprentissage basées sur les réseaux de neurones profonds. En particulier, les réseaux de neurones convolutifs (CNN), éventuellement combinés à des mécanismes d’attention [Vaswani et al. 2017] ou à des architectures de type Vision Transformer (ViT), sont devenus un standard pour de nombreuses tâches de reconnaissance en vision par ordinateur. Néanmoins, plusieurs études ont montré que ces réseaux ne sont pas infaillibles notamment lorsque le contexte change entre la base d’entraînement et la base de test (distribution shift). C’est par exemple le cas lorsque l’on apprend un modèle sur des données acquises dans des parcelles agricoles d’une zone géographique et que ce même modèle est appliqué sur d’autres parcelles ayant leur propre contexte agro-pédo-climatique. Dans de telles situations, la prédiction réalisée par un modèle de deep learning peut être erronée alors même qu’il peut accorder une forte confiance à cette prédiction. Si le manque de robustesse dans les décisions réalisées par des réseaux neuronaux est en partie inhérent à leur structure et aux méthodes d’apprentissage mises en œuvre, il est également explicable par les caractéristiques des bases de données utilisées et par leur manque d’exhaustivité.
Pour répondre à ces enjeux, une première stratégie consiste à intégrer des informations contextuelles ou auxiliaires (métadonnées) dans le processus d’apprentissage. Ces métadonnées telles que la localisation géographique, les conditions climatiques ou les caractéristiques du sol permettent d’enrichir la représentation de la scène observée. Plusieurs stratégies de fusion sont envisageables telles que la fusion précoce où les métadonnées sont concaténées aux descripteurs d’entrée du réseau, ou la fusion tardive où elles interviennent au niveau des couches de décision [Gadzicki et al. 2020]. Des approches récentes, comme la Metadata Normalization (MDN) [Lu et al. 2021] ou la Batch Normalization with Regularization (RegBN), visent à extraire des descripteurs décorrélés de ces métadonnées. Toutefois, ces méthodes reposent souvent sur des hypothèses de normalité qui peuvent ne pas être vérifiées en pratique.
Un second axe de recherche concerne la quantification de l’incertitude et la calibration des prédictions. Les modèles de deep learning tendent à produire des scores de confiance surestimés, sans garantie statistique sur la fiabilité de leurs décisions. Pour y remédier, la prédiction conforme (Conformal Prediction) [Vovk et al. 2005] propose un cadre théorique pour associer à chaque prédiction un ensemble de sortie garantissant un taux d’erreur contrôlé. Sa mise en œuvre repose sur la définition d’un score de non-conformité où différentes propositions ont été faites dans la littérature : Hinge loss (IP), Margin score (MS), Adaptive Prediction Set (APS), Regularized APS (RAPS), Penalized Inverse Probability (PIP) ou encore Regularized PIP (RePIP) [Melki et al. 2024]. Ces approches assurent des garanties marginales mais peinent à garantir des performances homogènes sur des sous-groupes de données présentant des conditions distinctes. Pour pallier cela, des extensions dites Mondrian Conformal Prediction ont été proposées, cherchant à garantir les performances par groupe, souvent définies à partir des métadonnées. Cependant, ces méthodes supposent la disponibilité des métadonnées au moment de l’inférence, ce qui n’est pas toujours le cas en pratique.
Enfin, des approches complémentaires comme la Test-Time Augmentation [Shanmugam et al. 2021] exploitent la diversité des transformations possibles (changement d’échelle, de contraste, etc.) sur les images lors de l’inférence. En estimant la variabilité des prédictions, ces stratégies permettent de renforcer la confiance associée à la décision sans nécessiter de réentraînement complet du modèle.
Objectif
L’objectif principal de cette thèse est de développer des méthodes de deep learning robustes pour la vision par ordinateur appliquée à l’agriculture, capables de s’adapter aux variations de contexte agro-pédo-climatique. L’enjeu est de concevoir des modèles d’IA de confiance, capables d’aider à la prise de décision dans des conditions réelles, tout en tenant compte de la variabilité et de la complexité des environnements agricoles.
Pour atteindre cet objectif principal, plusieurs objectifs intermédiaires sont définis :
- O.1. Prise en compte des métadonnées lors de l’apprentissage du modèle
Le premier objectif intermédiaire est de développer des modèles de deep learning permettant d’intégrer des informations décrivant le contexte agro-pédo-climatique (comme le type de culture/de cépage, le mode de conduite agronomique, les caractéristiques du sol, les conditions météorologiques lors de l’acquisition, etc.) afin de renforcer leur robustesse face aux changements de contexte et de mieux généraliser sur des données nouvelles.
- O.2. Quantification de l’incertitude via les prédictions conformes
Le second objectif est de développer des méthodes de prédictions conformes permettant de fournir des ensembles de prédiction valides, c’est-à-dire qu’au moins une proportion 1-α de ces ensembles contiennent la vraie classe, où α représente le niveau de risque fixé en amont par l’utilisateur. Ces méthodes visent à apporter des garanties statistiques sur les prédictions des modèles tout en s’adaptant au contexte agro-pédo-climatique des données de test.
- O.3. Exploitation de la diversité des observations à l’inférence
Le troisième objectif consiste à développer des stratégies de quantification d’incertitude permettant de tirer parti des techniques d’augmentation de données au moment de l’inférence (Test-Time Augmentation) pour exploiter la variabilité des observations. Cette approche ensembliste permettra de définir des ensembles de prédiction qui s’adaptent aux données de test.
- O.4. Approche intégrée combinant les contributions des objectifs O.1 à O.3
Le quatrième objectif consiste à proposer une version intégrative des contributions méthodologiques proposées dans les objectifs O.1 à O.3. Cela permettra d’évaluer à la fois la robustesse, la quantification des incertitudes et la valeur explicative des modèles développés, tout en contribuant à une meilleure compréhension du lien entre conditions d’acquisition et fiabilité des décisions des modèles d’IA.
Applications
Le doctorant contribuera au développement de modèles algorithmiques originaux qui seront par la suite validés dans divers contextes applicatifs pour une agriculture plus résiliente et durable grâce à l’IA de confiance. Pour cela, différentes applications sont envisagées comme des applications agri-environnementales pour l’estimation des stades phénologiques en viticulture ou encore la détection d’adventices pour la pulvérisation de précision. Le doctorant disposera différentes bases de données comme :
- Des bases de données d’images annotées d’organes de la vigne. Ces ensembles de données ont été constitués sur le site expérimental du château Luchey-Halde, dans le cadre de collaborations entre la cellule ImAgro de la plateforme IMS et le Digilab, composante numérique du FarmLab de Bordeaux Sciences Agro. Les acquisitions couvrent plusieurs années, à différentes dates/stades phénologiques et sous des conditions météorologiques variées, à l’aide de systèmes d’imagerie hétérogènes (capteurs fixes et capteurs mobiles).
- Des bases de données d’images de cultures et d’adventices : Le doctorant aura également accès à un ensemble complémentaire de bases de données d’images de cultures et d’adventices, comprenant à la fois des bases publiques telles que WE3DS et des bases propriétaires en collaboration avec des partenaires industriels.
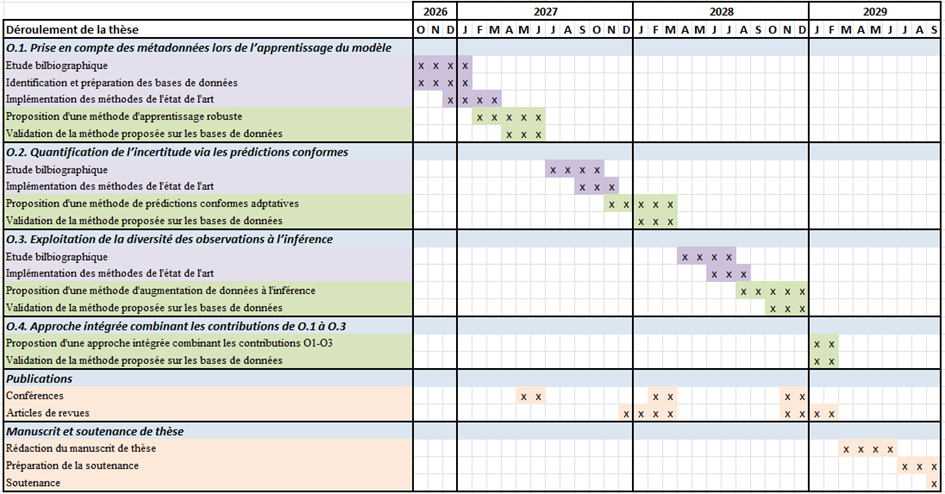
La figure ci-dessous présente le diagramme de Gantt prévisionnel de la thèse.
Bibliographie
[Gadzicki et al. 2020] K. Gadzicki, R. Khamsehashari and C. Zetzsche, Early vs Late Fusion in Multimodal Convolutional Neural Networks, FUSION, pp. 1-6, 2020.
[Lu et al. 2021] M. Lu, Q. Zhao, J. Zhang, K. M. Pohl, L. Fei-Fei, J. C. Niebles and E. Adeli. Metadata normalization. In CVPR, pages 10917–10927, 2021.
[Melki et al. 2024] P. Melki, L. Bombrun, B. Diallo, J. Dias and J.-P. Da Costa. The Penalized Inverse Probability Measure for Conformal Classification. In CVPR Workshops, pages 3512–3521, 2024.
[Shanmugam et al. 2021] D. Shanmugam, D. Blalock, G. Balakrishnan and J. Guttag, Better Aggregation in Test-Time Augmentation. In ICCV, pages 1194-1203, 2021.
[Vaswani et al. 2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin. Attention is All you Need. In NIPS, 2017.
[Vovk et al. 2005] V. Vovk, A. Gammerman and G. Shafer. Algorithmic learning in a random world. Springer-Verlag, Berlin, Heidelberg, 2005.
Profil recherché
- Vous êtes en dernière année d’un master ou école d’ingénieurs avec une spécialisation en traitement des images et/ou intelligence artificielle avec une appétence pour les applications agri-environnementales ou en école d’ingénieurs agronomes avec une spécialisation autour des technologies de l’information et de la communication (AgroTIC).
- Vous avez de bonnes connaissances sur le deep learning et les techniques d’apprentissage supervisé.
- Vous avez de solides compétences dans les langages de développement tels que Python et connaissez les principaux outils de l’intelligence artificielle (Pytorch).
- Vous êtes rigoureux et organisé, avec une appétence pour travailler dans un domaine interdisciplinaire (vision par ordinateur et applications agri-environnementales).
Organisation de la thèse et modalités de candidature
- Lieu : Laboratoire IMS – Groupe Signal et Image, campus de Talence (33)
- Durée : 3 ans à partir d’octobre 2026.
- Bourse : financement de thèse de l’école doctorale.
- Candidature : envoyer par mail un CV.
Contacts
- Lionel Bombrun, IMS/Bordeaux Sciences Agro, lionel.bombrun@ims-bordeaux.fr
- Jean-Pierre Da Costa, IMS/Bordeaux Sciences Agro, jean-pierre.dacosta@ims-bordeaux.fr



