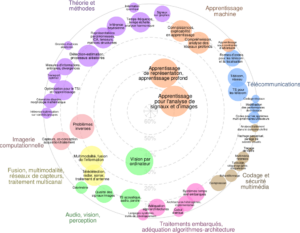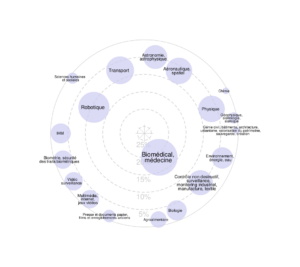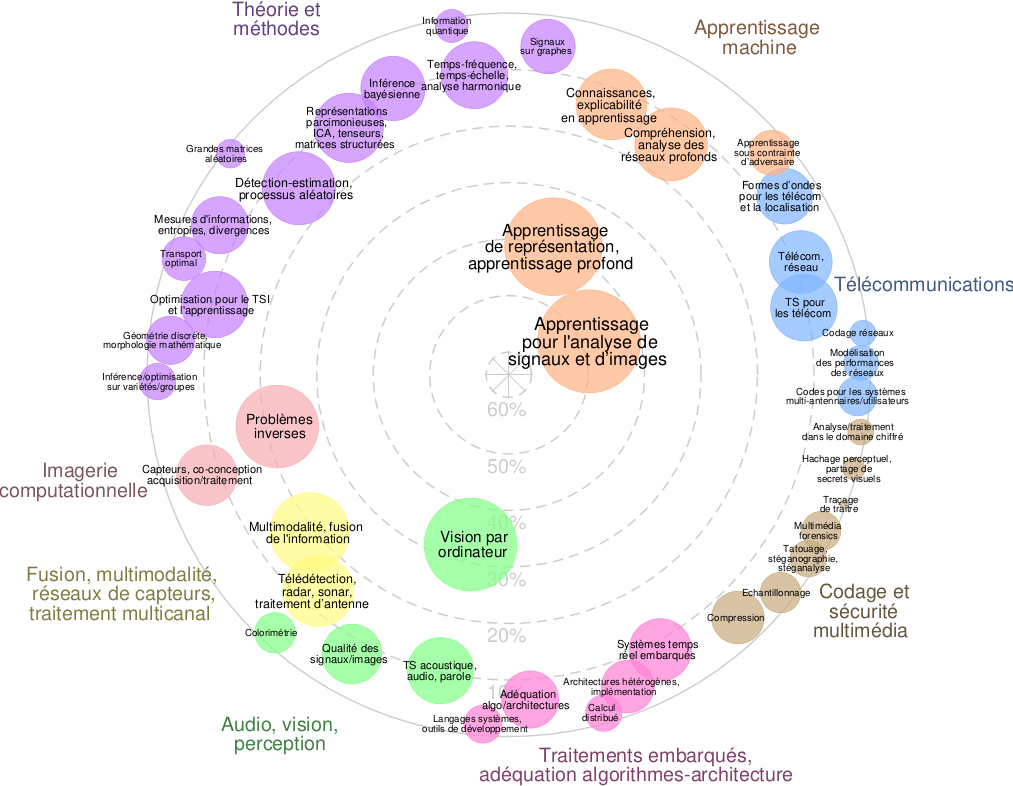
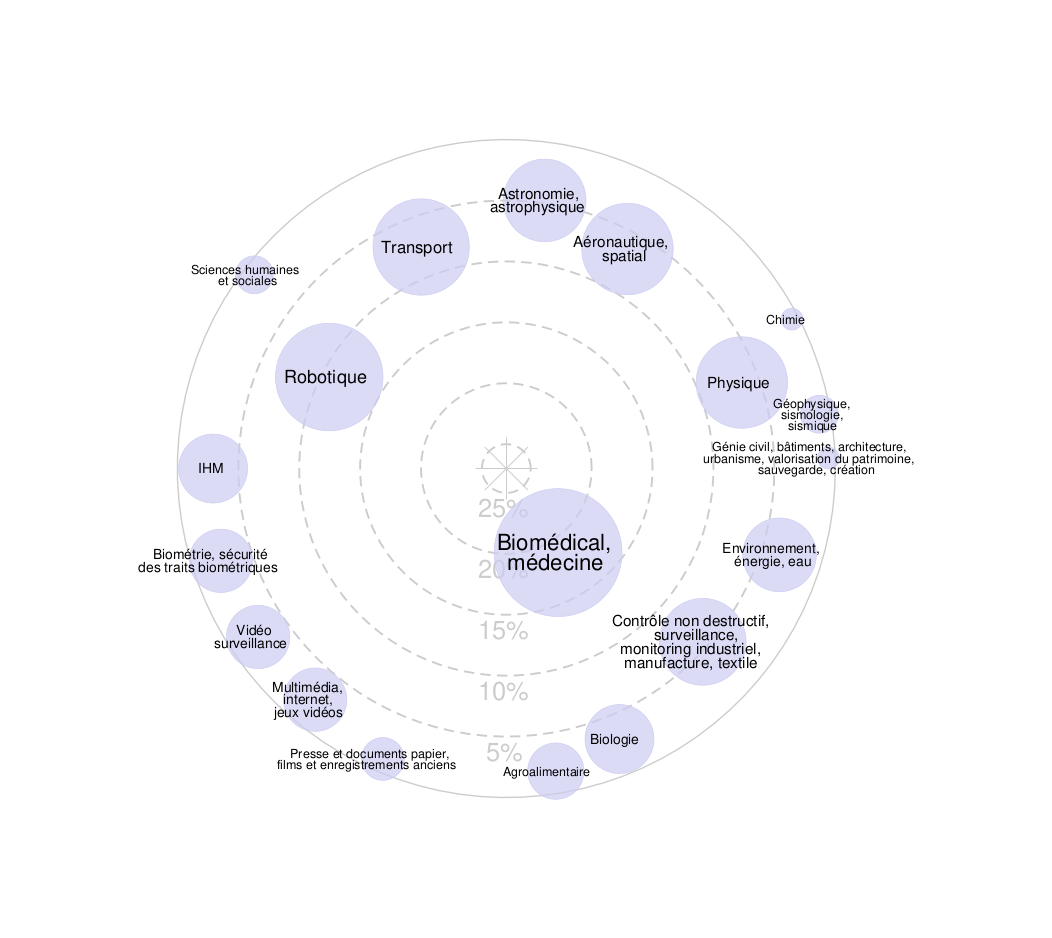
École d’Été Peyresq 2025
Thème Quantification d’incertitude Le GRETSI et le GdR IASIS organisent depuis 2006 une École d’Été...

9 Septembre 2024
Catégorie : Doctorant
In various scenarios, such as providing daily assistance to the elderly, aiding individuals recovering from severe injuries, or supporting commercial and recycling tasks, one can envision a robotic assistant handling garments by fetching, folding, and organizing clothes. In this project, we will focus on a key technical prerequisite for realizing this challenging scenario: advancing current computer vision techniques to enhance understanding and reasoning about the garment being manipulated. Specifically, we willaddressthe challenging tasks of recognizing a garment and its semantic parts in the visual content. The deep semantic understanding of garments is particularly challenging as garment objects depict complex topological and physical behaviors, involving strong self-occlusions and deformations of fabrics.
Recent successful image segmentation techniques in computer vision, such as SAM (Segment Anything Model) do not easily generalize to the detection of semantic parts, since the boundary assumption in object detection does not apply in semantic part detection where the presence of explicit boundaries is only optional. While its adaptation through prompting to specific domains like medical imagery have been demonstrated, SAM has shown exceptional proficiency only in certain objects and modalities, exhibiting inadequacy or ineffectiveness in other contexts. Advancing beyond FCN (Fully Convolutional Network) based per-pixel labeling, recent developments have introduced specialized context modules and various self-attention mechanisms, enabling the incorporation of contextual information. However, these models may not be particularly beneficial in our targeted settings, where the context is often limited. Methods specially developed for garment semantics mostly deal with 2D static images depicting clothes close to their canonical states seen by clear views, and focus on the segmentation of individual clothes rather than their semantic parts.
We will ground our 2D segmentation models on paired 3D objects, considering the highly flexible, self-occluding, and nonlinear dynamics nature of the garment object. Our 3D segmentation models will leverage temporal information during the transition to/from the garment’s canonical form, to effectively handle the highly deformed state. We will proceed with the following tasks:
1.Detection of garment types and semantic parts in canonical garments with partial occlusions, from 3D image input: A first step is to investigate the problem in relatively well-defined, simple settings: detection of garment categories and semantic part-segmentation in their canonical shapes. Although we will initially focus on static garments, utilizing static images, we also intend to explore dynamic garments in specific scenarios, using videos.
2.Detection of garment types and semantic parts in non-canonical state with significant deformations and occlusions: The main challenges occur when clothes are in their non-canonical states, due to a high level of deformation, which induces drastic shape changes and significant self-occlusions. To make the problem feasible, we will assume that a single garment is depicted in the image input. Two different approaches are considered: One, we start with identification of a garment in its canonical shape and develop methodology to transfer its semantics to the non-canonical form, by estimating nonrigid alignment between them. Two, we develop a bending-invariant method for the detection tasks, so that consistent results are obtained regardless of the garment state.
https://igg.unistra.fr/People/seo/StudentsJoboffer_files/PhD-GarSeM-2024-En.pdf